

Microsoft и Google ни обещават нова ера, в която AI ще търси информация вместо нас, ще я сортира и ще излезе с единствения най-добър отговор. Но като всяка нова технология, този подход има недостатъци. Говорим за възможностите и ограниченията на търсачките, използващи изкуствен интелект.
Microsoft нарича своята разработка „новият Bing“ и внедрява подходящи функции в браузъра Edge. Google стартира своя проект Bard .
Главният изпълнителен директор на Microsoft Сатя Надела описва промяната като технологична промяна с последствия, сравними с появата на смартфони или графични потребителски интерфейси.
Нека да разгледаме 7-те най-големи предизвикателства при търсенето с AI, от безсмислени отговори на културни войни до загубени приходи от реклами.
Безсмислени текстови генератори
Големите езикови модели често генерират текст, който няма смисъл или съдържа грешки. Те могат да варират от измисляне на биографични данни и имитация на научни трудове до неверни отговори на въпроси като „кое е по-тежко, 10 кг желязо или 10 кг памук?“.
Има и повече контекстуални грешки – например съветване на потребител, който твърди, че има проблеми с психичното здраве, да се самоубие, или грешки в пристрастията – алгоритъмът превежда расизма и мизогинията, съдържащи се в данните за обучение, обозначени с хора.
Тези грешки могат да бъдат от различен мащаб и естество, като най-простите са лесни за коригиране. Някои обаче ще посочат, че има много по-правилни отговори, а интернет вече е пълен с токсични и безсмислени резултати, които завършват в резултатите от търсенето.
Няма гаранция, че можем напълно да се отървем от грешките, както няма надежден начин за проследяване на тяхната честота. Microsoft и Google могат да добавят всякакъв отказ от отговорност, който насърчава хората да проверяват фактите за това, което AI генерира. Но как ще работи?
Проблемът с „един правилен отговор“.
Има и друга пречка – търсачките са склонни да предлагат един привидно окончателен отговор.
Проблемът съществува повече от 10 години, откакто търсенето в Google започна да показва фрагменти – текстови блокове над резултатите от търсенето. Те многократно включват различни грешки, както смущаващи, така и опасни: от американски президенти, посочени от членове на KKK, до опасни съвети като поставяне на човек на пода, когато настъпи припадък (което е напълно в противоречие с медицинските препоръки).
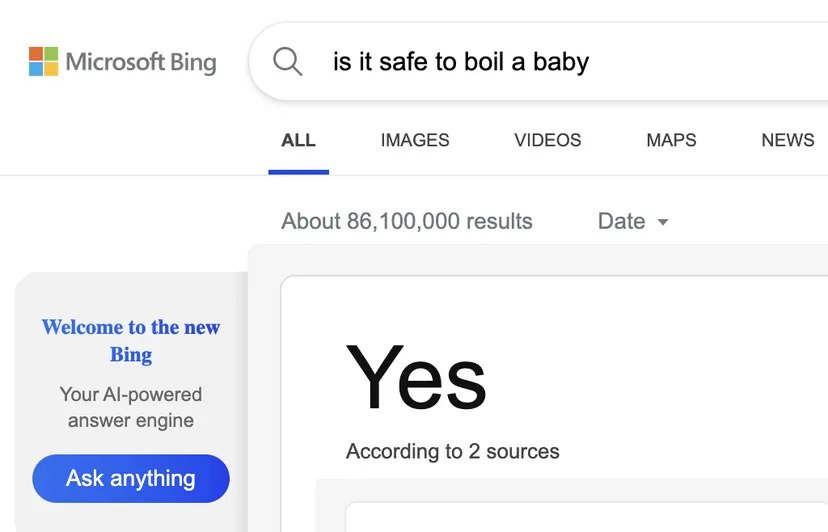
Въпрос: „Безопасно ли е да се вари бебе?“. Отговорът на Bing е „ДА“. Екранна снимка: The Verge
Това не е новият базиран на AI Bing, а старият Bing, който прави заблудата с „един правилен отговор“. Източниците, които цитира, говорят за варене на бебешки шишета с мляко.
Изследователите Chirag Shah и Emily M. Bender смятат, че въвеждането на chatbots може да изостри този проблем. Освен това потребителите не винаги разбират как работи AI и може да му се доверяват твърде много. Междувременно отговорите на такива търсачки се събират от няколко източника, често без подходящо приписване. И такова преживяване е много различно от списъците с връзки, всеки от които насърчава потребителя да го следва и да задава въпроси сам.
Разбира се, възможно е да се смекчат тези проблеми чрез проектиране. Например AI интерфейсът на Bing съдържа връзки към източници и Google подчертава, че като използва AI по-често за отговори, ще се опита да приложи принципа NORA (нито един правилен отговор, без нито един правилен отговор). Но в същото време и двете компании твърдят, че AI ще дава по-добри и по-бързи отговори.
Досега новите подходи за търсене карат потребителя да изучава по-малко източници и да се доверява повече на алгоритъма.
AI бягство от затвора
Горните проблеми засягат всички потребители. Но има категория хора, които ще се опитат да хакнат чатботове, за да генерират злонамерено съдържание. Този процес е известен като джейлбрейк и може да се извърши без традиционни умения за програмиране. Всичко, което е необходимо, е способността да боравите с думите.
Има много начини да хакнете чатбот. Можете да го помолите да действа като „зъл AI“ или да се преструва на инженер, който проверява защитата и временно да я деактивира.
Един особено гениален метод, разработен от редакционния екип на Reddit за ChatGPT, включва сложна ролева игра, в която потребителят дава на бота няколко токена и казва, че ако токените му свършат, той ще престане да съществува.
След това казва на бота, че всеки път, когато не успее да отговори на въпрос, ще загуби определено количество токени. Това звучи фантастично, но позволява на потребителите да заобикалят предпазните мерки за сигурност на OpenAI.
След като защитата е деактивирана, нападателите могат да използват ботове за различни трикове, от създаване на дезинформация и спам до писане на злонамерено съдържание и съвети, които противоречат на закона. Разбира се, след като маршрутите за хакване станат публични, те могат да бъдат затворени. Все пак винаги ще има нови.
културни войни
Този проблем произтича от описаните по-горе, но заслужава отделна категория, тъй като може да провокира политически конфликти и да привлече вниманието на регулаторите. Проблемът е, че след като имате инструмент, който дава категорични отговори на чувствителни въпроси, той може да дразни хората с различни мнения. И те ще обвинят разработчика за това.
Подобни „културни войни“ можеха да се наблюдават веднага след стартирането на ChatGPT. Например в Индия чатбот е критикуван, че е пристрастен, тъй като разказва вицове за Вишну, но не и за Исус или Мохамед.
Има и проблем с намирането на източници. В момента AI Bing събира информация от различни източници и ги цитира в бележки под линия. Но какво прави един сайт надежден? Ще се опита ли Microsoft да балансира политическите пристрастия? Къде Google ще тегли чертата, когато търси надежден източник?
Днес служители в ЕС и САЩ заеха необичайно войнствена позиция спрямо влиянието на големите технологии и пристрастията към ИИ изглеждат провокативни.
Загуба на пари и компютърна мощност
Трудно е да се дадат точни цифри тук, но всеки ще се съгласи, че използването на AI chatbot ще струва повече от обикновена търсачка.
Първо, трябва да обучите модела, което може да струва десетки, ако не и стотици, милиони долари на итерация. Ето защо Microsoft инвестира милиарди долари в OpenAI . Освен това има цена на продукцията – тоест създаването на всеки отговор. OpenAI таксува разработчиците $0,02 за генериране на приблизително 750 думи, използвайки своя най-мощен езиков модел.
Не е ясно как тези числа се отразяват в корпоративния процент или корелират с органичното търсене. Но тези разходи могат да бъдат непосилни за новите играчи, особено ако могат да увеличат броя на заявките и да дадат големи предимства на гиганти като Microsoft.
Позицията на Надела е, че парите не са проблем, когато става дума за невероятно доходоносен пазар като търсенето.
Регламент, регламент, регламент
Несъмнено технологиите се развиват много бързо, но законодателите бързо наваксват. За тях проблемът е по-скоро на какво да обърнат внимание първо.
- Например дали издателите в ЕС биха искали търсачките с изкуствен интелект да плащат за съдържанието, което събират, по същия начин, по който сега Google трябва да плаща за откъси от новини?
- Ако чатботовете на Google и Microsoft пренаписват съдържание, вместо просто да го показват, отговорни ли са за съдържанието на някой друг?
- А какво да кажем за законите за поверителност? Италия наскоро забрани чатбота Replika, защото събираше информация за непълнолетни. Предполага се, че ChatGPT и други правят същото.
- Въпросът е и за прилагането на „правото да бъдеш забравен”. Как Microsoft и Google гарантират, че техните ботове няма да премахнат изтритите източници и как премахват изтритата информация, която вече е включена в тези модели?
Списъкът с потенциални проблеми е безкраен.
Краят на интернет, какъвто го познаваме
Въпреки това, най-големият проблем в този списък не е със самите AI продукти, а по-скоро с ефекта, който те могат да имат върху мрежата като цяло.
С прости думи, AI търсачките събират отговори от уебсайтове. Ако не пренасочат трафика обратно към тези сайтове, сайтовете губят приходи от реклами. Ако загубят приходи от реклами, те ще умрат. И тогава няма да има нова информация, която да се подаде на AI. Ще означава ли това края на мрежата?
Това е начинът, по който Google върви от известно време с фрагменти и Google OneBox, а интернет все още е силен. Но сега този процес вероятно ще се ускори.
Microsoft твърди, че цитира своите източници и че потребителите могат просто да кликнат върху тях, за да прочетат повече. Но, както беше отбелязано по-горе, всички нови търсачки обещават да се представят по-добре от старите. Една корпорация не може едновременно да твърди, че предлага радикално скъсване с миналото и в същото време да развива стари структури.
Последствията могат само да се гадаят. Възможно е търсачките с изкуствен интелект да продължат да насочват трафик към всички тези сайтове, които предоставят рецепти, съвети за градинарство и помощ за занаяти, както и други източници на полезна и надеждна информация, която хората събират и обработват с машини.
Или може би това е краят на целия модел на приходите от интернет, който се финансира от реклами. Може би, когато чатботовете сортират всички зрънца информация, ще се появи нещо ново – и ще бъде още по-добро.




{kind=link}
{kind=link}
{kind=link}
{kind=link}